模型蒸馏是通过大模型的结果提升小模型预测准确率的方法。以此可以帮助我们减少线上模型部署的难度(减少内存,gpu,cpu 的使用)。
具体的做法如下:
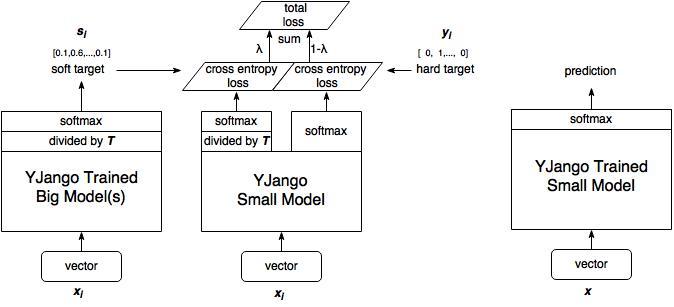
1、训练大模型:先用hard target,也就是正常的label训练大模型。
2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式(右图)使用。
一般认为,大模型比小模型能够描述复杂的问题,能够学得更复杂的模式。模型蒸馏能够让大模型学得的模式,间接的教给小模型
soft target
在模型蒸馏的时候,大模型的产生的soft target 是由温度T控制的。
通过调节温度能够控制soft target的平滑程度。使用soft target的原因可以看下面的解释:
信息量
hard target 包含的信息量(信息熵)很低, soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率,毕竟驴和马也是有点像的。)
软化
但是如果我们的big model的输出为[0.001,0.149,0.85],以这个为直接的学习目标,则最左边的类cross entropy的loss function中对于权重的更新贡献微乎其微,这样就起不到作用。把soft target软化(整体除以一个数值后再softmax),就可以达到0.1的数值。
再举个例子:如果要分类10个不同物体的图片,完全可以只输出一个节点,用一维输出来表示。得到1就是第一个物体,得到9就是第9个物体。但是这样做的话,输出层的这一个节点就有10个变体,会使建模时的熵增加。但是若用10个节点来分别表示,那么每个节点就只有一个可能的取值(也就是没有变体),熵就可以降到最低。可是问题又来了,如何确保这10个类就是所有变体?并没有把所有变体都摊开。比如解决下面的分类问题?
样本1: 2,3(样本1属于第二类和第三类)
样本2: 1,3,4(样本2属于第一类,第三类和第四类)
既属于第二类又属于第三类的样本就和既像驴又像马的样本图片一样。一种解决方式是重新编码,比如把属于2,3类的数据对应一个新的label(该label表示既是2又是3)。把所有变体全部摊开,比如有n个类,输出层的节点个数会变成$2^n-1$(-1是排除哪一类都不是的情况)。
一句话简言之,Knowledge Distill是一种简单弥补分类问题监督信号不足的办法.
参考:
1.https://www.zhihu.com/question/50519680 (YJango大神回答)
2.《Distilling the Knowledge in a Neural Network》